Refaktoryzacja do celu
1. Zakres artykułu
1.1. Rozpatrywane narzędzia
- Podejście ‘od problemu do rozwiązania’ wykorzystane przy refaktoryzacji
- Podejście systemowe - analiza części, większej całości oraz otoczenia
- Pętla ‘koncepcja-cele-implementacja-weryfikacja’ w praktyce, w sposób możliwy do powtórzenia.
- Celowość, iteracyjność, kryterium końca
1.2. Korzyści dla Was
Kiedy warto to przeczytać?
- Coraz trudniej Wam poruszać się po istniejącym kodzie i chcielibyście go przebudować - ale boicie się czegoś zepsuć.
- Macie kod i chcecie go przebudować - ale od czego zacząć? Co zmienić najpierw? Jak to zrobić, by się udało?
- Macie kilka potencjalnych wariantów zmiany kodu i chcecie móc porównać, która byłaby “lepsza”. I obronić swój wybór w zespole, by nie wyjść na łosia.
Co ja chcę Wam dać?
- Recepturę na refaktoryzację, która - jak na razie - pozwala mi na szybkie i skuteczne refaktoryzowanie (lub podjęcie decyzji o nie rozpoczynaniu refaktoryzacji).
- Chcę Wam pokazać, że refaktoryzacja nie jest czymś bardzo trudnym ani szczególnie strasznym. Jest trudna, ale nie aż TAK trudna jak się wydaje.
- Chcę to wszystko pokazać na pewnym studium przypadku (case study) - oraz przygotowałem małą solucję, na której możecie sami poćwiczyć.
2. Streszczenie myśli przewodniej artykułu
Jeżeli nie macie czasu przeczytać tego artykułu, lub jeśli chcecie sobie przypomnieć najważniejsze fragmenty artykułu, przeczytajcie ten punkt. To nie jest spis treści; to ekstrakt reszty artykułu (który stanowi opis techniki, po czym pojawia się case study):
- Refaktoryzacja to przebudowa nie zmieniająca wymagań funkcjonalnych.
- Refaktoryzacja tak “sama w sobie” nie ma sensu. Musi być “refaktoryzacja do czegoś”, pod kątem celu.
- Przebudowa istniejącego kodu wymaga przeanalizowania całości systemu, nie tylko przebudowywanego elementu systemu.
- Sukces refaktoryzacji zależy w większym stopniu od właściwego zidentyfikowania problemu i zaplanowania działań niż od umiejętności technicznych.
- Proponuję podejście: “Kontekst -> problem -> ideał -> (strategia <-> weryfikacja strategii) -> (działanie -> weryfikacja wyniku)”
- Działające techniki: iteracje, ewolucja a nie rewolucja, ustawienie warunków sukcesu.
- Bez zrozumienia problemu i domeny refaktoryzacja raczej nie przyniesie maksymalnego zwrotu - może nawet zaszkodzić.
- Jeśli nie wiesz, po czym poznasz sukces - nie wiesz kiedy przerwać i raczej nie obronisz rozwiązania przed krytyką.
Jeśli jeszcze jesteście zainteresowani, czas przejść do Bardzo Poważnego Wstępu.
3. Bardzo Poważny Wstęp
3.1. Refaktoryzacja?
Warto może tu zacząć od omówienia słowa “refaktoryzacja”. Zwykle refaktoryzacja rozumiana jest jako “zmiana struktury kodu bez wpływania na działanie samego programu - program ma robić to, co robił wcześniej”. Kryją się w tym trzy pułapki:
- “A co ten program robił wcześniej? A czy niczego nie zepsułem?”
- “To co ja w sumie mam robić, skoro ma robić to, co wcześniej?”
- “A… skąd będę wiedział, że już koniec pracy?”
Zwykle zaczynamy coś refaktoryzować, bo kod staje się “nieczytelny” czy “trudno się z nim pracuje”. Sęk w tym, że gdzie dwóch programistów tam trzy style programowania…
Bardzo łatwo przez to wszystko ugrzęznąć w bezcelowych kłótniach typu “ale Ty nie masz przecinka w komentarzu!”. Mieliście tak, że spłonęło Wam mnóstwo czasu przy dyskusji o to, czy “piszemy komentarze w kodzie” czy “nie piszemy komentarzy w kodzie - kod ma być samokomentujący”?
Teraz wyobraźcie sobie jak piękne i bezużyteczne wojny mogą wybuchać o wszystko podczas przeprowadzania refaktoryzacji. Aż chce się wziąć popcorn.
Nic dziwnego, że refaktoryzacja cieszy się ogólnie złą opinią:
- Z perspektywy biznesu: “czyli… będę płacić programistom za to, że nie będą niczego robili; no dobrze, coś tam dłubią..?”.
- Z perspektywy programistów: “to jest trudna, żmudna robota i na pewno coś się zepsuje - i oczywiście, wtedy to będzie moja wina. Aha, i jeszcze Czesiek Czepialski będzie kwestionował wszystko, co tam robię”

Niestety, refaktoryzacja jest czymś niemożliwym do uniknięcia. Wraz ze zmianą potrzeb biznesu oraz z powiększaniem się aplikacji będzie pojawiała się konieczność refaktoryzacji.
Postawię tu hipotezę, że program który nie jest przebudowywany jest już martwy - pytanie nie brzmi “czy umrze” tylko “kiedy umrze”.
3.2. Ale… dlaczego?! Po co to robić?!
Z uwagi na Stożek Nieoznaczoności.
Podejrzewam, że świetnie kojarzycie poniższy rysunek (bo ciągle trąbię o tym samym):
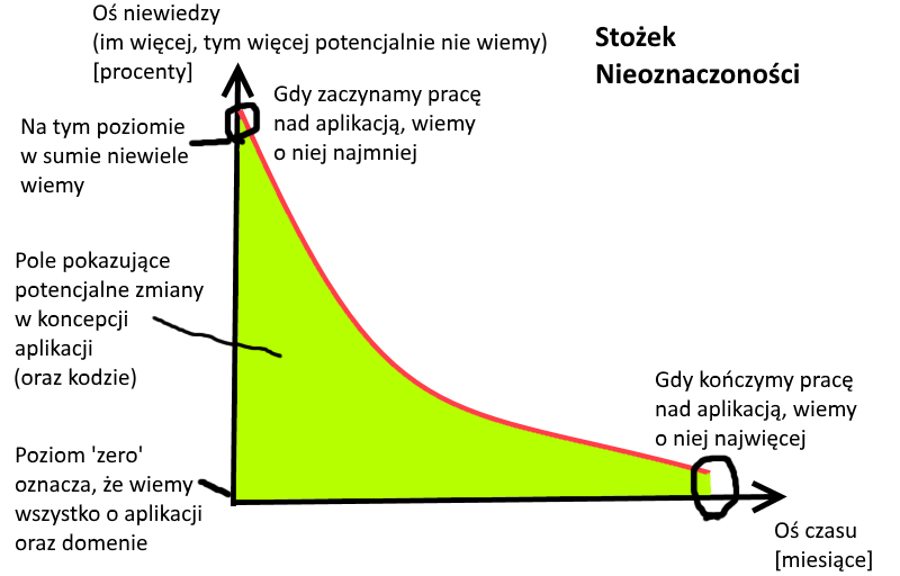
Z powyższego wynika, że najwięcej wiemy o aplikacji gdy kończymy nad nią pracować, a najmniej gdy zaczynamy. Tu pojawia się złośliwe pytanie: kiedy najczęściej podejmujemy kluczowe decyzje na temat aplikacji, takie jak na przykład… decyzje odnośnie architektury? React, Vue czy Angular? Baza grafowa czy SQLowa? Monolit czy mikroserwisy?
Niestety, wiele takich decyzji musimy podjąć na początku pracy. Wtedy, gdy najmniej wiemy.
Wraz z coraz lepszym zrozumieniem naszej aplikacji pojawia się myśl “gdybym tylko TO wiedział wcześniej, zrobiłbym inaczej”. Przez przypadek odcięliśmy sobie niektóre ścieżki. Zrobiliśmy niewłaściwe obiekty stanowe, nasz kod nie odpowiada naszej domenie…
Nie pociesza, że działaliśmy w dobrej wierze i zgodnie z zasadami sztuki. Nadal - pozmieniało się i teraz musimy się z tym męczyć. Albo przebudujemy kod tak, by dalej się z nim łatwo pracowało (oczywiście, bez psucia tego, co już działa), albo mamy trochę przechlapane.
Jak ze sprzątaniem - im dłużej to zaniedbujemy, tym więcej i trudniej. A jak nie sprzątamy, mamy coraz mniej miejsca i coraz trudniej się połapać.
Możemy oczywiście niczego nie robić…

Lepiej jednak nauczyć się refaktoryzować, nie sądzicie? ;-).
3.3. To co to JEST refaktoryzacja?
Gdybym miał spróbować złożyć definicję refaktoryzacji, powiedziałbym coś takiego:
“Refaktoryzacja to przebudowa aplikacji, która ma za zadanie zmienić strukturę kodu pod kątem jasno określonych celów. Przy okazji, nie mogą zmienić się żadne działania tej aplikacji.”
Dlaczego tak:
- “zmiana struktury pod kątem celów” oznacza “Coś nam nie pasowało. Wiemy, co. Wiemy, po czym poznamy sukces. Zmieniamy kod tak, by ten problem zniknął”.
- “nie mogą zmienić się żadne działania” oznacza po prostu “nic nie zepsuliśmy”. To, co działało wcześniej, to działa dalej. Jeśli zmieniliśmy jakieś działanie, to może naprawiliśmy błędy (lub wprowadziliśmy nowe) - ale to jest już coś innego niż refaktoryzacja.
Z perspektywy powyższej pseudo-definicji, optymalizacja (przebudowa kodu tak, by program działał szybciej lub wydajniej) jest formą refaktoryzacji (refaktoryzacja pod kątem prędkości / wydajności).
W klasycznej definicji jest inaczej, aczkolwiek nie rozumiem czemu ( każda zmiana kodu wpływa na prędkość działania kodu).
W ramach tego artykułu będę trzymał się własnej pseudo-definicji. U mnie działa ;-).
4. Pobieżnie - jak refaktoryzować?
4.1. Pobieżnie i szybko
Wiemy już “czemu”, czas dojść do “jak”. Z mojego punktu widzenia najważniejsze jest zapamiętanie kilku prostych zasad:
- Spojrzenie systemowe
- Kontekst -> problem -> ideał -> (strategia <-> weryfikacja strategii) -> (działanie -> weryfikacja wyniku)
- Iteracje, ewolucja a nie rewolucja
- Ustawienie warunków sukcesu
Koniec. To powinno wystarczyć. A teraz pozwólcie, że wyjaśnię dlaczego to wystarczy.
4.2. Spojrzenie systemowe
4.2.1. Co to jest system?
O tym powinienem napisać osobny artykuł. Jednak, w największym skrócie, “System to zbiór elementów i zachodzących między nimi relacji” (definicja cybernetyczna, za wikipedią).
Powyższe znaczy, że na system składa się:
- Każda CZĘŚĆ systemu musi działać poprawnie
- CAŁOŚĆ systemu musi działać poprawnie
- Do poprawnego działania system potrzebuje poprawnego OTOCZENIA.
Brzmi to dumnie i niezrozumiale, więc pokażę to na przykładzie:
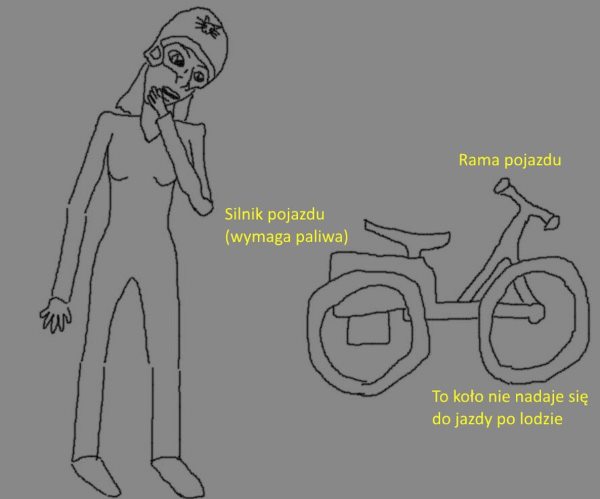
Mamy zatem dziewczynę patrzącą na pojazd roweropodobny, ale napędzany paliwem. Powiedzmy, że chcemy usprawnić taki pojazd pod kątem prędkości - dostaliśmy polecenie usprawnienie silnika.
- Jeżeli silnik będzie działał gorzej / nie będzie działał, pojazd jako całość nie pojedzie (CZĘŚĆ)
- Jeżeli mamy najlepszy możliwy silnik, ale niekompatybilny z paliwem tego pojazdu, pojazd jako całość nie pojedzie (CAŁOŚĆ)
- Jeżeli mamy bardzo potężny silnik (np. z samolotu), pojazd jako całość jest niemożliwy do kontroli i jest niebezpieczny (CAŁOŚĆ)
- Jeżeli silnik jest za słaby, bo pojazd waży 100000 ton, to pojazd jako całość nie pojedzie (CAŁOŚĆ)
- Jeżeli mamy świetnie złożony pojazd i wstawimy go w -100 stopni Celsjusza, pojazd nie pojedzie (OTOCZENIE)
Innymi słowy, by pojazd jako SYSTEM działał poprawnie, musimy zapewnić to, że:
- Każda CZĘŚĆ pojazdu musi działać prawidłowo
- CAŁOŚĆ pojazdu musi działać prawidłowo
- Pojazd działa w sprzyjającym OTOCZENIU
I to właśnie jest spojrzenie systemowe. Wszystko wpływa na wszystko i każdy ruch ma tysiące efektów ubocznych.
4.2.2. Przykład spojrzenia systemowego przy refaktoryzacji
Podczas pracy nad naszą aplikacją spotkałem się z poniższym problemem:
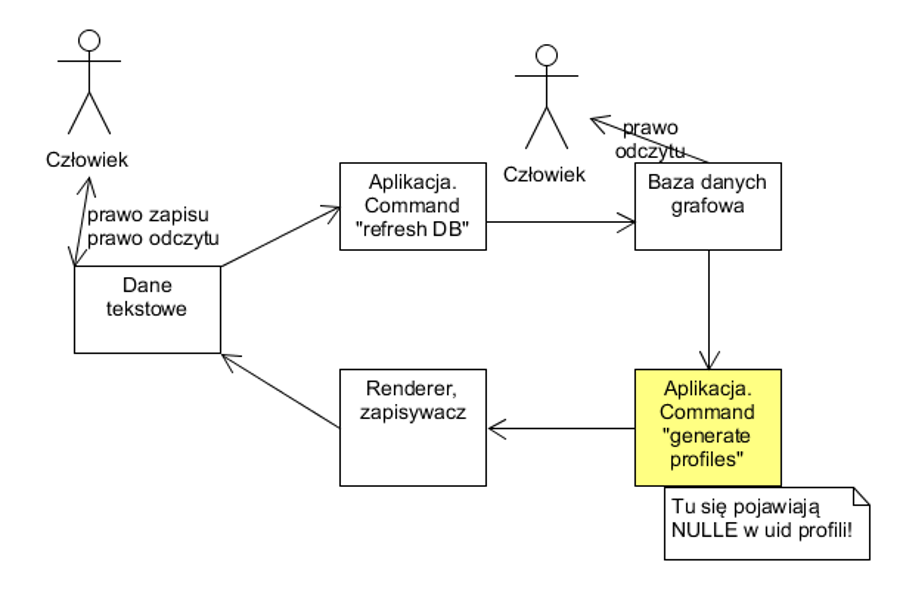
Gdy nasza aplikacja dochodziła do etapu “Generate Profiles”, rzucany był wyjątek. Po zbadaniu sprawy okazało się, że w naszej bazie grafowej część danych potrzebnych do zbudowania profili było nullami. Generacja profili nie była zabezpieczona przed nullami i stąd ten wyjątek.
Proste do naprawienia, prawda? Wystarczy ufortyfikować “Generate Profiles” i zapewnić, że jeśli pobierze nulla z bazy danych to… właśnie, co?
Nulle były wyrzucane na dość istotnym polu “uid”, czyli “unikalny identyfikator”. Nie było możliwości zbudowania prawidłowego profilu, bo nie dało się mu przypisać unikalnego identyfikatora (to takie coś w stylu PESELu). Uid powstaje przez połączenie “numeru” oraz “nazwiska” danej postaci (upraszczając).
Przeanalizujmy możliwe rozwiązania:
Naprawienie “Generate Profiles”:
- muszę wymyśleć jakąś wartość domyślną dla UID przy wyciąganiu z bazy
- gdy wyciągam z bazy, mam tylko ten jeden byt, który wyciągnąłem
- każdy inny klocek czytający z bazy danych też musi być naprawiony
- w bazie nadal są nulle, co jest niezgodne z domeną.
Zmiana “Refresh DB”:
- muszę wymyśleć jakąś wartość domyślną dla UID podczas podawania do bazy
- gdy wkładam do bazy, mam więcej danych niż do bazy podane; tu jest prościej
- każdy inny klocek czytający z bazy jest automatycznie bezpieczny
- w bazie nie ma nulli, problem domenowo nie istnieje
Oczywistym rozwiązaniem była w tym wypadku zmiana “Refresh DB” - upewnienie się, że nigdy do naszej bazy grafowej nie trafią dane mające “uid” jako nulla. Problem nie leżał w CZĘŚCI (Generate Profiles) a w CAŁOŚCI (Refresh DB podawał nulle do bazy). W CZĘŚCI jedynie ów problem się objawiał.
Problem rozwiązany, programista idzie na kawę.
Czy aby na pewno?
Stara, dobra zasada głosi “nigdy nie ufaj użytkownikowi”. Nasz użytkownik ma dostęp do dwóch punktów systemu - do danych tekstowych i do bazy grafowej. Przeanalizujmy OTOCZENIE.
- Jeżeli użytkownik może modyfikować tylko dane tekstowe, to rozwiązaliśmy problem - cokolwiek nie będzie napisane, nasza poprawka rozwiąże problem.
- Jeżeli jednak użytkownik może modyfikować bazę grafową, to może ręcznie podać niewłaściwe pole. W tym wypadku oprócz zmian w “Refresh RD” musimy wprowadzić też zmiany w “Generate Profiles”. Musimy zarówno rozwiązać problem na poziomie CAŁOŚCI jak i zabezpieczyć się na poziomie CZĘŚCI.
Mam nadzieję, że ten prosty przykład pokaże Wam, dlaczego podejście systemowe jest potrzebne przy refaktoryzacji. Bez tego typu analizy refaktoryzacja bywa całkiem zabawna ;-).
4.3. Od problemu do weryfikacji wyniku.
Pętla:
Kontekst -> problem -> ideał -> (strategia <-> weryfikacja strategii) -> (działanie -> weryfikacja wyniku)
jest kolejną formą “od problemu do rozwiązania”, “top-down” i innych konceptów tego typu:
- Musimy wiedzieć co chcemy osiągnąć, co nas boli i gdzie jest faktyczny problem
- Musimy móc stworzyć obraz idealny, w którym nas już nie boli i świat jest piękny
- Musimy wybrać sposób dojścia do tego obrazu idealnego od stanu aktualnego
- Musimy to przeprowadzić i sprawdzić, czy każdy z ruchów prowadzi nas do sukcesu
- Musimy móc udowodnić, że osiągnęliśmy sukces
Różnica polega na tym, że refaktoryzacja wymaga spojrzenia systemowego (poprzedni punkt), więc:
Z uwagi na Otoczenie, nie możemy rozpatrywać samego Problemu w izolacji. Musimy spojrzeć na nasz Problem w kontekście całości systemu, w którym się poruszamy (pamiętacie przykład z nullami w bazie grafowej?).
Z uwagi na to, że dotykamy Całości a nie tylko Części, nie możemy rozpatrywać Problemu bez spojrzenia na to, co istnieje dzisiaj. Refaktoryzacja to jest przebudowa czegoś, co już istnieje - musimy więc rozumieć co dzisiaj istnieje. Stąd “Stan Idealny” - czego oczekujemy?
Z uwagi na to, że mamy “stan aktualny” i “stan idealny”, musimy móc wyprowadzić jakąś formę przejścia “od tego co mamy dziś do tego co chcemy mieć”. To jest wybór strategii dojścia do stanu idealnego. Już na tym etapie można na bazie kryteriów sukcesu wybrać, które podejścia są “lepsze” a które “gorsze”.
No i wszystkie te plany nie są wiele warte, póki faktycznie nie spróbujemy tego zrealizować. Pozostaje potem tylko udowodnić, że to co zrobiliśmy faktycznie pomogło.
Brzmi prosto, nie? ;-).
4.4. Podejście iteracyjne i ewolucyjne
W idealnym świecie moglibyśmy chwilę podumać i nagle - spadłoby na nas oświecenie. Wiem już, jak przeprowadzić tą refaktoryzację! Natchniony, siadam do klawiatury i piszę! Wszystkie testy - zielone! Wszystko działa! To było TAKIE proste!
…tyle, że to się nie zdarza.
Nawet najlepszy plan prędzej czy później musi być zweryfikowany. O czymś nie pomyśleliśmy. Czegoś nie sprawdziliśmy. Czegoś nie wiemy.
Jest OK.
Wszelkie próby refaktoryzacji powinny być podzielone na małe kroki, gdzie:
- każdy krok ma określone kryterium sukcesu i jest możliwy do zweryfikowania
- każdy krok jest logicznym następstwem poprzednich kroków
- każdy krok prowadzi do rozwiązania Wielkiego Problemu
- każdy krok jest możliwy do zrealizowania w ciągu maksymalnie jednego dnia
Najważniejsze parametry to te trzy pierwsze; czasem nie ma możliwości zbudowania kroku, który da się zamknąć w jednym dniu (acz to sprawia, że ryzyko refaktoryzacji jest naprawdę wysokie).
“Big Bang Refactoring” (refaktoryzacja typu “Wielki Wybuch” - z niczego powstaje rozwiązanie) jest bardzo rzadkim rozwiązaniem i najczęściej tak średnio działa. Jeżeli nie ma innej możliwości i trzeba zrobić to “jednym ruchem”, nie znamy domeny i ogólnie mamy przechlapane, polecam technikę Strangler Application, zaproponowaną przez Martina Fowlera. Dokładniejszy opis wraz z przykładami tutaj. Sprawdziłem; ta technika faktycznie działa.
4.5. Warunki sukcesu
Kluczem do udanej refaktoryzacji jest prawidłowe zdefiniowanie faktycznego problemu z jakim mamy do czynienia, jak i tego, co uznamy za sukces.
Bardzo łatwo jest powiedzieć “refaktoryzacja się udała, bo kod jest bardziej czytelny”. Jeszcze łatwiej jest powiedzieć “czytelny oznacza to, że główny programista powie, że jest bardziej czytelny”. Widziałem już takie przypadki.
Sęk w tym, że ów główny programista był przyzwyczajony do C, aplikacja była pisana w C# i “bardziej czytelny kod” oznaczał usunięcie połowy LINQ i generyków ORAZ przekształcenie kodu w kod imperatywny, drastycznie utrudniając przebudowę aplikacji. Tak więc, jak to mówił klasyk, “operacja się udała, pacjent zmarł”.
Co za niefart.
Trzeba pamiętać o tym, że mamy do czynienia z systemem. Każda zmiana kaskaduje na cały system - na CZĘŚĆ, CAŁOŚĆ i nasz system nadal musi być w stanie działać w określonym OTOCZENIU. To właśnie powoduje, że poważne refaktoryzacje są dość niebezpieczne; wydawałoby się, że jest lepiej - a jednak pogorszyliśmy sytuację.
Kryteria sukcesu muszą uwzględniać interesy wszystkich interesariuszy i spojrzenie na całość systemu. W innym wypadku będzie ciężko.
4.6. Ostatnie słowo przed przykładem
Sporo tego. Jednak jak długo metodycznie podchodzicie do problemu i pamiętacie o każdym kroku, powinno się bez większego problemu udać.

5. Przykład z omówieniem
5.1. Opowieść o problemie
W styczniu 2018 roku poprosiłem swoją kochaną Żonę, by dopisała mi do pisanej przez nas aplikacji (rdbutler) parsowanie Planów dla Profili i Frakcji. Ku mojemu ogromnemu zdziwieniu, usłyszałem, że sam mogę sobie to pisać. Ona ma dość pracy z wyrażeniami regularnymi - a już zwłaszcza moimi ;-).
Gdy w 2016 roku jeszcze uczyłem się wyrażeń regularnych (czasem zwanych regexami) nigdy nie zakładałem, że będę miał aż tyle parsowania tekstu w tej aplikacji. To sprawiło, że aplikacja nie była przystosowana do wielu różnorodnych regexów.
Dla wyjaśnienia co to jest wyrażenie regularne: wyobraźcie sobie, że mamy następujący tekst:
# streszczenie:
summary data
## Different subheader
Text
# Different Header
Uruchamiam funkcję o nazwie “ExtractSummarySection” podając powyższy tekst. Dostaję w odpowiedzi:
summary data
A wszystko dzięki niewielkiemu dziwnemu ciągowi znaków - wyrażeniu regularnemu - w środku owej funkcji:
^#\s[Ss]treszczenie[:|\s]*$(.+?)(\Z|^#{1,2}\s\w+)
który oznacza mniej więcej coś takiego:
- Zacznij od początku linijki (znak ‘^’)
- Znajdź znak ‘#’, potem dowolny znak pusty jak ‘spacja’ (czyli ‘\s’)
- Znajdź słowo “Streszczenie” lub “streszczenie”
- Potem może być dwukropek albo spacja albo nic; tak czy inaczej, następna linijka (‘$’)
- TERAZ WSZYSTKO JEST WAŻNE (‘(.+?)’) AŻ DO MOMENTU:
- …albo koniec tekstu, albo ‘#’ czy ‘##’, po których jest pusty znak
I wyciągnij wszystko co tam ważne było. Jak spojrzycie na tekst wyżej, jedynym takim tekstem było “summary data”.
(Dla zainteresowanych, wizualizacja tego wyrażenia regularnego pod linkiem poniżej; trzeba skopiować i wkleić ręcznie: https://regexper.com/#%5E%23%5Cs%5BSs%5Dtreszczenie%5B%3A%7C%5Cs%5D*%24(.%2B%3F)(%5CZ%7C%5E%23%7B1%2C2%7D%5Cs%5Cw%2B)
)
Wyrażenie regularne to trochę jakby “język dopasowywania tekstu do wzoru” (przepraszam za uproszczenie).
Sęk w tym, że w naszej aplikacji takie coś trzeba było pisać z palca za każdym razem. I moja Żona zażądała, bym to zmienił, albo nie będzie dotykała parserów.
Zrobiłem to. Ostateczna refaktoryzacja dotknęła około 600-800 linijek kodu na przestrzeni 25 klas; w tym artykule skupimy się na pojedynczym wycinku zgodnie z naszą procedurą działania.
Jak zatem można to przebudować?
5.2. Kontekst oraz Problem
Aplikacja o której mówię pracuje z ogromną ilością plików tekstowych (zdecydowanie ponad 1000), dodawanych ręcznie przez ludzi. Ekstrakcja przy użyciu wyrażeń regularnych dotyka kilkunastu typów nagłówków. Realizowane jest to przez wyrażenia regularne takie jak:
^#\s[Ll]okalizacje[:|\s]*$(.+?)(\Z|^#\s\w+)
^#\s[Ss]treszczenie[:|\s]*$(.+?)(\Z|^#{1,2}\s\w+)
^##\s[Kk]ontynuacja:*\s*(.+)#{1,2}\s
###\s[Kk]ampanijna\s*(.+?)#{1,3}\s
Uproszczony problem w formie kodu C# tutaj
Jak zapewne widzicie, powyższe rozwiązanie posiada bardzo duży poziom duplikacji kodu. Co gorsza, gdybyśmy chcieli dodać nowy typ nagłówka, musimy napisać nowe wyrażenie regularne i naprawdę dużo kopiować i wklejać. Niewygodne; nic dziwnego, że moja Żona zaprotestowała. Miała rację - to trzeba było naprawić. W innym wypadku rozszerzalność parsera tekstu byłaby zagrożona.
Nazwijmy Problem:
- Dodawanie ekstrakcji nowego nagłówka wymaga pisania nowego wyrażenia regularnego. Łatwo się pomylić i jest to żmudna, wredna robota.
- Dodawanie ekstrakcji nowego nagłówka wymaga dużej ilości prymitywnego kopiowania i wklejania. Ten kod jest bardzo podobny; to strata czasu.
- Osoba niedoświadczona w wyrażeniach regularnych nie jest w stanie pracować z tą aplikacją na poziomie parsowania tekstu.
Dobrze, mniej więcej to mamy. Czas przejść więc do kolejnego kroku.
5.3. Stan Idealny
Nie jest to szczególnie trudne w tym wypadku:
- Chcę, by skacowany i niedoświadczony programista potrafił dodać nową ekstrakcję nagłówka bez możliwości zrobienia głupiego błędu.
- Chcę, by dało się szybko i bez nieprzyjemności dodać nową ekstrakcję nagłówka. Bez kopiowania i wklejania.
- Chcę, by praca z parsowaniem tekstu była tak łatwa jak praca z kodem Pythona na innych poziomach aplikacji.
To powyżej wygląda dobrze. Zauważcie - wszystkie te rzeczy są dość mierzalne i pozwalają nam wartościować rozwiązania na lepsze i gorsze.
5.4. Strategia i Weryfikacja: próba 1
Stawiam hipotezę, że najlepszą strategią rozwiązania tego problemu będzie zrobienie funkcji (lub metod; jak wolicie). Niedoświadczony programista lubi pracować z funkcjami, acz niekoniecznie z wyrażeniami regularnymi. W tej chwili przykładowe funkcje ekstrakcji wyglądają tak:
string locationText = ExtractLocationSection(inputText);
string summaryText = ExtractSummarySection(inputText);
W moim świecie idealnym oczekuję, że to będzie wyglądało jakoś tak:
string locationText = ExtractSection(inputText, "#\s[Ll]okalizacje[:|\s]*$(.+?)(\Z|^#\s\w+)");
string summaryText = ExtractSection(inputText, "#\s[Ss]treszczenie[:|\s]*$(.+?)(\Z|^#{1,2}\s\w+)");
Hm… jakkolwiek pozbyłem się problemu z duplikacją kodu, muszę na poziomie funkcji podać jako parametr konkretne wyrażenie regularne. Moja Żona odmówiła pracy nie z funkcjami a właśnie z owymi wyrażeniami. To sprawia, że to rozwiązanie nie rozwiązuje “głównego” problemu. Nie jest ono głupie, ale nie jest wystarczające.
5.5. Strategia i Weryfikacja: próba 2
Stawiam inną hipotezę - najlepszą strategią rozwiązania tego problemu będzie parametryzacja wyrażeń regularnych. Niech istnieją funkcje - tak, jak zaproponowałem w poprzednim rozwiązaniu. Ale to, co tu ważniejsze - niech te wyrażenia regularne będą “składane” z komponentów.
Ale z jakich komponentów?
Jak przyjrzymy się tym wszystkim wyrażeniom regularnym, to są one bardzo podobne. Każda interesująca nas grupa zaczyna się pewną liczbą znaków ‘#’ i kończy się pewną liczbą znaków ‘#’. Każde ma jakiś “tekst”, jakąś nazwę nagłówka. Może da się je jakoś sensownie ujednolicić…
Chciałbym zobaczyć coś takiego:
string locationText = ExtractSection(inputText, "Lokalizacje", starting = 1, blocking = 1);
string summaryText = ExtractSection(inputText, "Streszczenie", starting = 1, blocking = 2);
Gdyby mi się udało, to rozwiązałbym ten problem:
- Każdy programista tej aplikacji potrafi pracować z funkcjami. Nie ma tam żadnych wyrażeń regularnych.
- Trudno się tu pomylić i łatwo oraz szybko można to wykorzystać. Nie jest to ani żmudne ani wredne.
- Poprzednie rozwiązanie z funkcjami rozwiązało problem duplikacji kodu.
Super. Pierwsze rozwiązanie nie zadziałało, ale drugie tak. Weryfikacja udana, mamy swoją strategię dojścia do stanu idealnego. Na tym etapie nie wiem jeszcze JAK to zrobić, ale wiem już przynajmniej gdzie chcę dojść.
5.6. Działanie i Weryfikacja
5.6.1. Ujednolicenie wyrażeń regularnych
Spójrzmy jeszcze raz na nasze cztery główne wyrażenia regularne:
^#\s[Ll]okalizacje[:|\s]*$(.+?)(\Z|^#\s\w+)
^#\s[Ss]treszczenie[:|\s]*$(.+?)(\Z|^#{1,2}\s\w+)
^##\s[Kk]ontynuacja:*\s*(.+)#{1,2}\s
###\s[Kk]ampanijna\s*(.+?)#{1,3}\s
Niezbyt to czytelne. Wiemy (z domeny), że wszystkie nagłówki zaczynają się od nowej linijki, ale trzy wyrażenia mają znak ‘^’ a jedno nie. Wiemy, że wszystkie powinny ignorować wielkie i małe znaki… to akurat łatwo rozwiązać. Zamiast:
Regex.Matches(text, "[Ll]okalizacje", RegexOptions.Singleline | RegexOptions.Multiline);
można użyć dodatkowej flagi:
Regex.Matches(text, "lokalizacje", RegexOptions.Singleline | RegexOptions.Multiline | RegexOptions.Ignorecase);
Tego typu zmiany pozwolą na uczytelnienie i ujednolicenie wyrażeń regularnych. Dzięki temu łatwiej uda się je nam parametryzować dalej.
- Oczekuję wyniku: Łatwiej będzie wydobyć mi parametry z uproszczonych wyrażeń regularnych.
- Kryterium sukcesu: Da się je ujednolicić tak, by różniły się tylko rzeczami parametryzowalnymi.
- Kryterium sukcesu: Nic się nie zepsuło; co działało to działa
5.6.2. Ekstrakcja nazwy nagłówka
Mając starą funkcję i nowe wyrażenie regularne, coś w stylu:
ExtractLocationSection(inputText)
# Lokalizacje[:|\s]*$(.+?)(\Z|^#{1,1} \w+)
Spróbuję wyciągnąć wszystkie nazwy nagłówków poza wyrażenie regularne. Zbudować coś takiego:
ExtractSection(inputText, "Lokalizacje")
# NAZWA_NAGŁÓWKA[:|\s]*$(.+?)(\Z|^#{1,1} \w+)
- Oczekuję wyniku: Da się coś takiego zrobić dla każdego wyrażenia regularnego w aplikacji.
- Kryterium sukcesu: Nie istnieje ani jeden przypadek dla którego to jest niemożliwe. Wszystko albo nic.
- Kryterium sukcesu: Nic się nie zepsuło; co działało to działa
5.6.3. Ekstrakcja liczby zaczynających ‘#’
Mając starą funkcję i nowe wyrażenie regularne, coś w stylu:
ExtractSection(inputText, "Lokalizacje")
# NAZWA_NAGŁÓWKA[:|\s]*$(.+?)(\Z|^#{1,1} \w+)
Spróbuję wyciągnąć liczbę startowych ‘#’ tak, by działały zarówno:
# streszczenie[:|\s]*$(.+?)#{1,2}\s
## kontynuacja[:|\s]*$(.+?)#{1,2}\s
Jakoś taki wynik:
ExtractSection(inputText, "Lokalizacje", start = 1)
#{1, ILOŚĆ_START} NAZWA_NAGŁÓWKA[:|\s]*$(.+?)(\Z|^#{1,1} \w+)
- Oczekuję wyniku: Da się coś takiego zrobić dla każdego wyrażenia regularnego w aplikacji.
- Kryterium sukcesu: Nie istnieje ani jeden przypadek dla którego to jest niemożliwe. Wszystko albo nic.
- Kryterium sukcesu: Nic się nie zepsuło; co działało to działa
5.6.4. Ekstrakcja liczby kończących ‘#’
Nie będę się powtarzał, jak powyżej.
5.7. Weryfikacja CAŁOŚCI
Mamy nowe funkcje. Są takie jak Stan Idealny. W teorii, wszystko powinno działać.
Pytanie: czy FAKTYCZNIE dostaliśmy takie korzyści jakich oczekiwaliśmy od przejścia Stan Aktualny -> Stan Idealny ? Czy nasz Stan Idealny rozwiązuje Problem w Kontekście?
Jeżeli tak, to commit i push. Refaktoryzacja zakończona powodzeniem. Jeżeli nie, to git reset –hard. Refaktoryzacja zakończona niepowodzeniem na poziomie koncepcyjnym. Musimy to opracować i zdefiniować problem jeszcze raz.
W naszym wypadku - to zadziałało. Czas dodawania nowego parsowanego bytu spadł z około 30 minut do niecałych 5 minut, nie licząc konieczności dodania testów w wypadku starego rozwiązania (w nowym testy są zbędne; testujemy funkcję techniczną jednorazowo).
W literaturze uzupełniającej znajdziecie linki do ćwiczeń i faktycznej refaktoryzacji, jak jesteście zainteresowani.
6. Podsumowanie
6.1. Podejście metodyczne
Jak - mam nadzieję - pokazałem, podejście metodyczne pozwala na w miarę spokojne podejście do refaktoryzacji. Zacznijmy od tego, że zamiast kłócić się o szczegóły możemy skupić się na tym, co ważne - po co to robimy, co chcemy osiągnąć i jak to zmierzymy. Samo to pozwala na dramatyczną oszczędność czasu.
Refaktoryzacja nigdy nie jest łatwa - warto więc sobie pomóc przy użyciu dowolnej techniki, która działa. Oczywiście, w tym artykule użyłem prostego przykładu - ale im większy i bardziej skomplikowany problem, tym cenniejsze jest metodyczne podejście.
6.2. Sprzeczne cele
Poważnym problemem przy refaktoryzacji jest to, że różne cele refaktoryzacji bardzo często są sprzeczne:
- Zróbmy kod bardziej czytelnym i rozszerzalnym (większe rozdrobnienie kodu na funkcje, klasy i moduły)
- Zróbmy kod szybszym i bardziej wydajnym (scalenie do DLLek, wstawki assemblerowe, zmniejszenie czytelności)
Często zdarza się, że podczas dyskusji o refaktoryzacji dwie osoby mają różne idee tego, DLACZEGO aplikacja jest refaktoryzowana; czym jest ów Stan Idealny. Najlepszym rozwiązaniem w tym wypadku jest usiąść i porozmawiać. Niestety, trzeba zaakceptować smutny fakt - nie ma rozwiązań idealnych. Dążenie do pierwszej korzyści często utrudnia dojście do drugiej korzyści. W takim wypadku ustalamy co ma wyższy priorytet - i działamy.
6.3. Musimy rozumieć domenę i kod
Z uwagi na Kontekst oraz Stan Idealny - musimy zrozumieć domenę, w której działa aplikacja. Refaktoryzując bez zrozumienia co ów program ma robić, możemy się nieźle wkopać z uwagi na Stożek Nieoznaczoności.
Z uwagi na Stan Aktualny, CAŁOŚĆ i OTOCZENIE - musimy rozumieć kod, który w chwili obecnej działa w refaktoryzowanej aplikacji. Tak jak z moim nieszczęsnym przykładem z nullami w bazie grafowej - bez znajomości istniejącego systemu nie byłbym w stanie znaleźć prawidłowego rozwiązania.
Tak naprawdę NIGDY nie refaktoryzujemy kodu. Zawsze dostosowujemy istniejący kod do tego, by lepiej rozwiązywał konkretny problem biznesowy. Dlatego ta domena jest tak ważna. A nie wiedząc, co mamy dziś - nie wiemy jak najmniejszym kosztem to przebudować.
6.4. Nie wszystko da się zrobić
Spotkałem się pewnego dnia z przypadkiem takim, jak poniżej:
- Biznes: potrzebujemy odpowiedź w ciągu 300 milisekund
- Programista: da się zrobić; teraz zajmuje 500 milisekund
- …minął dzień
- Programista: Nie ma sprawy, zajmuje już tylko 50 milisekund
- Biznes: …ale to jest strona internetowa. Nadal mamy dwie sekundy
- Programista: …no to się nie da zrobić… nad tym nie ma kontroli
Tak, wracamy do problemu Otoczenia. Czasami macie np. dwa dni na refaktoryzację a potrzebowalibyście tydzień. W takich okolicznościach także nie da się zwyciężyć. Czasem najlepszym rozwiązaniem jest stwierdzenie “nie, nie robimy refaktoryzacji”.
6.5. Refaktoryzacja jako problem polityczny
Bardzo często głównym problemem nie jest zmiana kodu a obronienie swojego rozwiązanie w Zespole. Lub sprzedanie swojego rozwiązania Biznesowi.
Jeżeli budujecie w prawidłowy sposób Koncepcję (w tym wypadku: Kontekst i Problem oraz Stan Idealny), powinniście być w stanie znaleźć rzeczowe argumenty w formie przystępnej dla odbiorcy. Nie daje Wam to gwarancji sukcesu, ale zwiększa prawdopodobieństwo.
Nie rozpatrywałem szczególnie w tym artykule refaktoryzacji jako problemu politycznego. Może kiedyś.
6.6. Jak zatem zacząć refaktoryzację?
Ja osobiście wykorzystuję następującą procedurę (omijam elementy związane ze zdobyciem wsparcia politycznego ze strony reszty zespołu i biznesu):
- Nazywam Problem w konkretnym Kontekście.
- Analizuję całość systemu (Część, Całość, Otoczenie) by określić zakres refaktoryzacji i czy ja jestem w stanie ją przeprowadzić w sensownym czasie.
- Sprawdzam z innymi członkami zespołu, czy oni TEŻ mają ten problem - co najbardziej ich boli. Doprecyzowuję Problem.
- Przechodzę przez pętlę: Kontekst -> problem -> ideał -> (strategia <-> weryfikacja strategii) -> (działanie -> weryfikacja wyniku). Upewniam się, że nie idę w perfekcję a w naprawienie tego, co jest największym problemem. Dopisuję testy tam, gdzie się da / ma to sens.
- Sprawdzam, czy nowa całość jest lepsza niż stara całość. Przeprowadzam wszystkie testy.
- Sprawdzam, czy rozwiązuje to problemy innych członków zespołu. Jak nie, upewniam się, że nie utrudniłem innym członkom zespołu pracy lub przyszłych zmian mających im pomóc.
Jeśli nie wiem jak coś przeprowadzić, pytam osobę po prawej stronie / szukam w wyszukiwarce czy Stack Overflow.
Jak długo pamiętacie o celowości i mierzalności każdego kroku, powinno się udać. Pamiętajcie, że refaktoryzacja to trochę eksploracja - trzeba szukać i eksperymentować z rozwiązaniami. Nie zawsze pierwsze rozwiązanie będzie najlepsze. Czasem wpadniecie w ślepą uliczkę i trzeba się wycofać (bo nie zauważyliście czegoś w Otoczeniu czy Całości).
Zupełnie jak sprzątanie ;-).
7. Wykazanie korzyści
7.1. Przypomnienie korzyści
Czy zatem dostaliście to, co Wam obiecałem na początku? Dla przypomnienia, obiecałem Wam to:
Kiedy warto to przeczytać?
- Coraz trudniej Wam poruszać się po istniejącym kodzie i chcielibyście go przebudować - ale boicie się czegoś zepsuć.
- Macie kod i chcecie go przebudować - ale od czego zacząć? Co zmienić najpierw? Jak to zrobić, by się udało?
- Macie kilka potencjalnych wariantów zmiany kodu i chcecie móc porównać, która byłaby “lepsza”. I obronić swój wybór w zespole, by nie wyjść na łosia.
Co ja chcę Wam dać?
- Recepturę na refaktoryzację, która - jak na razie - pozwala mi na szybkie i skuteczne refaktoryzowanie (lub podjęcie decyzji o nie rozpoczynaniu refaktoryzacji).
- Chcę Wam pokazać, że refaktoryzacja nie jest czymś bardzo trudnym ani szczególnie strasznym. Jest trudna, ale nie aż TAK trudna jak się wydaje.
- Chcę to wszystko pokazać na pewnym studium przypadku (case study) - oraz przygotowałem małą solucję, na której możecie sami poćwiczyć.
7.2. Dowody pośrednie
Receptura dostarczona, tak jak i case study. Solucja w materiałach uzupełniających. Przejdźmy do ciekawszego fragmentu:
Jeśli trudno Wam się poruszać po istniejącym kodzie i boicie się go zepsuć - receptura pozwoli podjąć decyzję, czy refaktoryzacja jest wskazana / konieczna czy też nie. Działając zgodnie z ową recepturą minimalizujecie szansę błędnej refaktoryzacji, bo wszystko opieracie na korzyściach i niewielkich ruchach. Oczywiście, jesteście w stanie podjąć błędne decyzje podczas refaktoryzacji, ale wprowadziłem tam tyle kroków weryfikacji, że to nie jest aż tak proste.
Dodajmy do tego myślenie systemowe: część, całość i otoczenie. Jeżeli faktycznie wykorzystujecie te wszystkie techniki, uważam, że nie macie się czego bać. Nie każda refaktoryzacja się udaje, ale zawsze zostaje git reset –hard ;-).
Od czego zacząć i jak w ogóle przeprowadzać refaktoryzację? Od Problemu do Rozwiązania. Nie pokazałem Wam konkretnych technik; osobiście nie znalazłem bardzo użytecznych i uniwersalnych technik. Ja podchodzę do każdej refaktoryzacji indywidualnie, acz zgodnie z zaproponowaną procedurą. Jeśli chcecie poczytać o pojedynczych transformacjach, polecam Wam katalog Martina Fowlera.
Jak porównać różne strategie refaktoryzacji i jak obronić swoją koncepcję? Przez posiadanie twardych, mierzalnych celów, faktów i argumentów. Cały fragment tekstu odnośnie definiowania stanu idealnego i korzyści z owej transformacji moim zdaniem spełnia tą obietnicę.
Jeżeli nie uważacie tych dowodów za wystarczające, zawiodłem. Nadal jednak pozostaję dość pewny siebie ;-).
8. Literatura uzupełniająca
Tym razem jedynie kod. Ćwiczenie w C# i przykład rzeczywisty w Pythonie.
- Solucja w C#, przy użyciu której możecie przeprowadzić prostszą wersję tej refaktoryzacji
- Potrzebujecie Visual Studio (może być Community Edition); solucja jest pisana w C# i plik *.sln znajduje się w folderze trainings_code_snippets\RefactoringWithRegex_1801\RefactoringWithRegex_1801
- Po ściągnięciu *.zip lub git pull, mstest powinien sam znaleźć 6 testów. Wszystkie testy powinny być zielone.
- Jeśli coś nie działa, ważne są tylko dwa pliki: TestExtractStoryData do testów i ExtractStoryDataFromText do kodu. Możecie zrobić nową solucję i dodać projekt zwykły i testowy jeśli trzeba. Do zwykłego dodajcie ExtractStoryDataFromText, do testowego - TestExtractStoryData. Zadziała.
- Ta solucja nie robi niczego. Przeprowadźcie refaktoryzację zgodnie z instrukcją w TestExtractStoryData. Niech testy są zielone ;-).
- Faktyczny commit po rebase opisywanej refaktoryzacji (uwaga: większej niż przykład)
- Branch, na którym jest cała przeprowadzona refaktoryzacja, łącznie z błędami: od 10 stycznia do końca
9. Metadane artykułu
- Czas poświęcony na budowę szkicu: 2 godziny
- Liczba osób korygujących szkic (poza autorem): 1
- Czas poświęcony na napisanie i korektę artykułu: 13 godzin
- Liczba osób korygujących artykuł (poza autorem): 1
- Czas poświęcony na przebudowę artykułu później: 1 godzina
- Liczba osób korygujących artykuł po publikacji (poza autorem): ?
- Liczba błędów / modyfikacji artykułu po wydaniu: ?
- Czas poświęcony na korekcję błędów: ?
Szkic, dla chętnych zobaczenia jak “robi się kiełbasę”, tutaj